- موتور جستجو چگونه کار میکند
- موتور جستجو چگونه میخزد
- فهرست موتور جستجو چیست ؟
- رتبه بندی موتور جستجو
- خزیدن: آیا موتور جستجو میتواند وب سایت شما را پیدا کند؟
- Robots.txt
- رباط گوگل چگونه با فایل Robots.txt رفتار میکند
- تعریف پارامتر های URL در GSC
- آیا خزنده ها میتوانند محتوای مهم را پیدا کنند ؟
- آیا محتوای شما در پشت فرمهای ورود به سیستم پنهان است
- آیا به فرم های جستجو اعتماد می کنید؟
- آیا متن در محتوای غیر متنی پنهان است؟
- آیا موتور های جستجو میتوانند جهت یابی سایتتان را دنبال کنند؟
- اشتباهات رایج ناوبری که باعث میشود خزدنه های نتوانند سایت شما را کامل ببینند
- آیا معماری اطلاعات واضحی دارید؟
- آیا از نقشه سایت استفاده میکنید؟
- آیا خزنده ها هنگام تلاش برای دسترسی به URL های شما با خطا روبرو میشوند؟
- کد های سری 400: هنگامی که خزنده های موتور جستجو در اثر خطای سمت کاربر به محتوای شما دسترسی ندارد؟
- کد های سری 500: هنگامی که خزنده های موتور جستجو در اثر خطای سمت سرور به محتوای شما دسترسی ندارد؟
- تساوی لینک
- فهرست کردن
- تجربه کاربری
- فهرست کردن: موتور جستجو چگونه صفحات شما بررسی و ذخیره میکند؟
- آیا میتوانم چگونگی دیده شدن صفحات توسط خزنده گوگل را ببینم؟
- آیا تابحال صفحات از فهرست حذف شده است؟
- به موتور جستجو بگویید که چگونه سایت شما را فهرست کند
- رتبه بندی: موتور های جستجو چگونه URL ها را رتبه بندی می کنند؟
- موتور های جستجو چه میخواهند؟
- نقشی که لینک ها در سئو بازی می کنند
- نقشی که محتوا در سئو بازی می کند
- RankBrain چیست؟
- این برای سئو به چه مفهومی است؟
- معیارهای تعامل: ارتباط، علیت یا هر دو؟
- گوگل چه می گوید؟
- تست های چه چیزی نشان میدهد؟
- سیر تکاملی نتایج جستجو
- ارتباط
- مسافت
- برجستگی
- رتبه بندی ارگانیک
- [جایزه!] تعامل محلی

موتور های جستجو چگونه کار میکنند
همانطور که در بخش اول اشاره کردیم, موتور های جستجو ماشین های پاسخگویی هستند. آنها برای کشف کردن, فهمیدن, و و ساماندهی محتوای موجود در اینترنت ساخته شده اند تا به سوالاتی که در جستجو پرسیده میشود, مرتبط ترین پاسخ را بدهند.
برای نمایش در نتایج جستجو, باید محتوای شما برای موتور های جستجو قابل دیدن باشید. به طور قطع مهمترین قطعه پازل سئو این است. اگر سایت شما قابل یافتن نیاشد, هیچ راهی برای نمایش در SERPs (صفحات نمایش جستجو نیست).
موتور جستجو چگونه کار میکند
موتو های جستجو بر اساس سه کارکرد اصلی کار میکند
- خزیدن: جستجوی اینترنت برای محتوا, بررسی کد/محتوای هر لینکی که پیدا میکنند
- فهرست کردن: ذخیره و ساماندهی محتوایی که هنگام فرایند خزیدن پیدا میشود. وقتی که صفحه فهرست شد, برای نمایش در جستجو های مرتبط در آماده میشود
- رتبه بندی: ارائه تکه هایی از محتوا که بهترین پاسخ به را به سوال جستجو شده میدهد, که به معنی مرتب سازی نتایج بر اساس مرتبط بودن تا کمتر مرتبط بودن است.
موتور جستجو چگونه میخزد
خزیدن به فرایند اکتشاف که موتور های جستجو در آن تیمی از ربات ها (با نام عنکبوت ها یا خزنده ها نیز شناخته میشود) برای یافتن محتوای جدید و بروز ارسال میکنند.محتوا می تواند به صورت متغییر - میتواند صفحه وب, یک تصویر, یک ویدیو, یک PDF, غیره باشد - اما بدون در نظر گرفتن فرمت, محتوا توسط لینک ها پیدا میشود.

گوگل بات با واکشی چند صفحه شروع میکند, و پس از آن لینک های که در آن صفحات هستند دنبال میکند تا صفحات جدید را پیدا کند. با پریدن میان لینکها, خزنده میتواند محتوای جدید را پیدا و به فهرست شان که کافین نامیده میشود اضافه کند -- یک دستابیس عظیم از URL های کشف شده - تا بعدا هنگامی که یک جستجوگر دنبال اطلاعاتی است که محتوای موجود در آن URL برایش مناسب است, آن را بازیابی و استفاده کند.
فهرست موتور جستجو چیست ؟
پردازش و ذخیره اطلاعاتی که موتورهای جستجو پیدا میکند یک فهرست کردن است, یک دیتابیس هجیم از اطلاعاتی که کشف شده و به اندازه ای خوب سات که برای جستجوگران نمابش داده شود.
رتبه بندی موتور جستجو
هنگامی که یک جستجو انجام می دهد, موتور جستجو فرست اش را برا یافتن محتوایی با ارتباط بالا جستجو میکند و سپس آن محتوا را با این امید که مشکل جستجوگر را حل کند مرتب سازی میکند. این مرتب سازی نتایج جستجو براساس ارتباطشان را رتبه بندی مینامند. در حالت کلی شما میتواند فرض کنید که وب سایتی که رتبه بندی بالاتری را دارد, موتور جستجو فکر میکند بیشترین ارتباط را به سوال جستجو شده دارد.
این امکان وجود دارد که موتور جستجو را از خزیدن قسمت هایی از وب سایتتان منع و مسدود کنید, یا موتور جستجو را راهنمایی کنید تا از ذخیره صفحاتی خاص در فهرستشان دوری کند. درحالی که انجام این کار ممکن است دلیلی داشته باشد, اگر شما میخواهید محتوایتان توسط جستجوگران پیدا شود, ابتدا باید مطمئن شوید که برای خزیدن و فهرست شده قابل دسترس است, در غیر این صورت , بهتر است همان مخفی بماند.
در آخر این بخش شما مفادی که برای کار کردن با موتور جستجو نیاز دارید خواهید داشت, بجای آن که مخالفش باشید.
خزیدن: آیا موتور جستجو میتواند وب سایت شما را پیدا کند؟
همانطور که یاد گرفته اید, باید مطمئن شوید سایت شما خزیده و فهرست شدنش پیش نیاز نمایش در SERPs است. اگر شما از قبل یک سایت دارید, بظر ایده خوبی می آید تا با دیدن تعادا صفحات که فهرست شده شروع کنید. این کار اطلاعات خوبی درباره اینکه گوگل در حال خزیدن و فهرست کردن صفحاتی شما میخواهید یا آنهایی که نمی خواهید میدهد.
یک راه برای چک کرن صفحات فهرست شده “site:domainshoma.ir” است, یک اپراتو پیشرفته جستجو. به گوگل بروید و “site:domainshoma.ir” در نوار جستجو تایپ کنید. این نتیجه ای است که گوگل در فهرست خود برای سایت مشخص شده دارد.
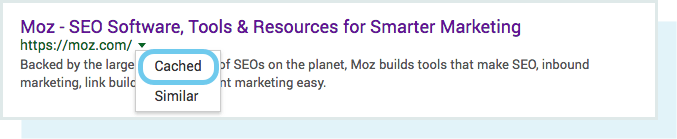
تعداد نتایج گوگل (About XX results) دقیق نیست, اما یک تصویر کلی از صفحات فهرست شده سایت شما و اینکه درحال حاضر چگونه در صفحات نتایج نمایش داده میشود, به شما میدهد.
برای دریافت نتایج دقیق تر, از گزارش پوشش فهرست در کنسول جستجوی گوگل (Google Search Console) استفاده کنید.اگر در حال حاضر یک حساب کنسول جستجوی گوگل ندارید, می توانید برای اکانت کنسول جستجو گوگل به صورت رایگان ثبت نام کنید. با این ابزار, شما میتوانید سایت مپ ها (لیست لینک) را برای سایتتان ثبت و تعداد صفحات ثبت شده ای که به فهرست گوگل اضافه شده را در میان بقیه چیز ها مانتیور و بررسی کنید.
اگر در هیچ جای نتاییج جستجو نمایش داده نمی شوید, برای چرای آن چند دلیل وجود دارد:
- سایت شما کاملا جدید است و تاکنون بررسی نشده است.
- سایت شما هیچ لینکی از سایت های خارجی ندارد.
- جهت یابی (لینک دهی به قسمت های مختلف سایت) سایت شما کار را برای خزیدن رباط سخت میکند.
- سایت شما حاوی برخی از کدهای اساسی به نام دستورالعمل های خزنده است که موتورهای جستجو را مسدود می کند.
- سایت شما به دلیل تاتیک های اسمپی توسط گوگل جریمه شده است
اکثر افراد به این اطمینان دارند که گوگل صفخات مهمشان را پیدا میکند, اما به آسانی فراموش میکنند که احتملا صفحاتی است که شما نمی خواهید توسط رباط گوگل پیدا شود.ا ممکن است این شامل URL های قدیمی که دارای محتوای کوتاه؛ URL های تکراری (مانند پارامتر های مرتب و فیلتر شده برای فروشگاه اینترنتی), صفحات ویژه کد تبلیغاتی, صفحات مرحله بندی یا آزمایشی و غیره. برای جلوگیری از دسترسی رباط گوگل از این بخش ها و صفحات از robots.txt استفاده کنید.
Robots.txt
Robots.txt در مسیر ریشه وب سایت قرار گرفته است (برای مثال yourdomain.com/robots.txt) و قسمت هایی که باید و یا نباید خزیده شوند را در کنار اینکه با چه سرعتی از طریق دستور العمل های خاص robots.txt خزیده شوند را به موتورهای جستجو پیشنهاد میدهد.
رباط گوگل چگونه با فایل Robots.txt رفتار میکند
- اگر رباط گوگل نتواند فایل robots.txt سایت شما را پیدا کند, شما خزیدن سایت شما میکند.
- اگر رباط گوگل فایل robots.txt را پیدا کند سایت شما را پیدا کند, معمولاً به پیشنهادها پایبند بوده و به جستجوی سایت می پردازد.
- اگر رباط گوگل هنگام تلاش برای دسترسی به فایل robots.txt به خطا بر بخورد و نتواند تشخیص بدهد که یکی وجود دارد یا نه, سایت را بررسی نخواهد کرد.
همه ربات های وب robots.txt را دنبال نمیکنند. افرادی با نیت (مانند پیدا کنند لیست ایمیل) رباتی میسازند که از پروتکول پیروی نمیکند. در حقیقت, بعضی از افراد بد از فایل robots.txt برای پیدا کردن محل محتوای خصوصی شما استفاده میکنند. با اینکه بلاک کردن خزنده ها از صفحاتی مانند لاگین و مدیریت به نظر عاقلانه به نظر می رسد تا در فهرست نمایش داده نشود, قرار دادن آدرس این URL ها در robots.txt قابل دسترس به صورت عمومی به این معنی است که افرادی با اهداف مخرب به راحتی می توانند آن را پیدا کنند. بهتر این صفحات را فهرست نشوند و پس لاگین برای آنها محافظی بسازید به جای اینکه در فایل robots.txt قرار دهید.
شما میتوانید درباره این در قسمت robots.txt مرکز یادگیری ما بیشتر بخوانید.
تعریف پارامتر های URL در GSC
بعضی از سایت ها (بیشتر در سایت های فروشگاهی رایج است) برای URL های متعدد مختلف با ضمیمه کردن پارامتر های خاص به URL ها محتوای یکسان را ارئه میدهند. اگر تاکنون به صورتی آنلاین خرید کرده باشید, احتمالاً جستجوی خود را از طریق فیلترها محدود کرده اید. برای مثال ممکن است “کفش های در آمازون” جستجو کنید و پس از آن جستجوی خود را با اندازه کفش , رنگ و سبک دوباره اصلاح کنید . هر بار که اصلاح میکنید, URL به صورت مختر تغییر میکند.
https://www.example.com/products/women/dresses/green.htmhttps://www.example.com/products/women?category=dresses&color=greenhttps://example.com/shopindex.php?product_id=32&highlight=green+dress&cat_id=1&sessionid=123$affid=43
گوگل از کجا می فهمد که کدام نسخه را برای جستجوگران ارئه دهد ؟ گوگل کاملا و به خوبی میتواند مشخص کند که کدام URL مناسب است, اما شما میتوانید از پارامترهای URL در کنسول جستجوی گوگل استفاده کنید و به گوگل بگویید دقیق می خواهید چگونه با صفحات شما رفتار کند. اگر شما به ربات گوگل بگویید "URL ای با این پارامتر را بررسی نکن", پس شما اساسا از ربات گوگل می خواهید تا محتوا را پنهان کند, که این می تواند باعث حذف شدن این صفحات از نتایج جستجو شود. اگر این پارامتر ها صفحات تکراری ایجاد کنند این چیزی است که شما میخواهید, اما اگر میخواهید این صفحات فهرست شوند کار درستی نیست.
آیا خزنده ها میتوانند محتوای مهم را پیدا کنند ؟
حالا که چند تاکتیک درباره اطمینان از دور ماندن خزنده های موتور جستجو از محتوا بی اهمیت می دانید, بیایید درباره بهینه سازی که به پیدا کزدن صفحات مهم توسط ربات گوگل کمک میکند یاد بگیریم. بعضی مواقع ربات گوگل میتواند قسمت های مختلف سایت شما با خزیدن آن پیدا کند. اما صفحات یا بخشهای دیگر ممکن است به یک دلیل یا بیشتر مخفی بماند. بسیار مهم است که مطمئن شویم موتور های جستجو میتوانند محتوایی که شما میخواهید فهرست شود را پیدا کنند.
از خودتان این را بپرسید: آیا این ربات میتواند از تمام است من را بررسی کند, و فقط دسترسی خالی به آن ندارد؟

آیا محتوای شما در پشت فرمهای ورود به سیستم پنهان است
اگر نیاز است کاربر وارد سایت شود, فرمی را پر کند, یا قبل از دسترسی به محتوای خاص به نظرسنجی ها پاسخ دهد, موتور های جستجو نمی توانند صفحات محافظت شده را ببینند. یک خزده به طور یقیین نمی تواند وارد سایت شود.
آیا به فرم های جستجو اعتماد می کنید؟
ربات ها نمی توانند از فرم های جستجو استفاده کنند. بعضی از افراد فکر میکنند اگر در سایت خود از فرم های جستجو استفاده کنند, موتور های جستجو با استفاده از جستجو های کاربرانشان همه جیز را پیدا کنند.
آیا متن در محتوای غیر متنی پنهان است؟
فرم های مدیای غیر متنی (تصاویر, ویدیو, تصویر متحرک و غیره) نباید برای نمایش متن که می خواهید فهرست شود استفاده شود. درحالی که موتورهای جستجو در تشخیص تصاویر در حال پیشرفت هتند؛ درحال حاضر هیچ تضمینی وجود ندارد که بتوانند تصویر را بخوانند و درک کنند. همیشه بهترین کار اضافه کرد متن از طریق نشان گذاری <HTML> در وب سایتتان است.
آیا موتور های جستجو میتوانند جهت یابی سایتتان را دنبال کنند؟
همانطور که خزنده نیازمند کشف سایت شما از طریق لینک های سایت های دیگر هستند, نیازمد مسیر یابی لینک ها برای راهنمایی به صفحه ای از صفحه دیگر در وب سایت خودتان است. اگر صفحه ای دارید که می خواهید موتورهای جستجو آن را پیدا کنند، اما از صفحه دیگری به آن پیوند داده نشده است ، تقریبا آن صفحه نامرئی است. بسیاری از سایتها با ایجاد ساختار ناوبری سایت خود به گونه ای که برای موتورهای جستجو غیرقابل دسترسی است ، اشتباه می کنند و مانع دستیابی آنها از لیست شدن در نتایج جستجو می شوند.

اشتباهات رایج ناوبری که باعث میشود خزدنه های نتوانند سایت شما را کامل ببینند
- داشتن ناوبری موبایل که اطلاعات متفاوتی از ناوبری دسکتاب دارد
- مدل هایی از ناوبری که که ایتم های منو بصورت HTML نیست, مانند ناوبری هایی که بر به جاوا اسکریپت وابسته هستند. گوگل در درک و خزیدن جاوا اسکریپت بسیار بهتر شده, اما همچنان کامل نیست. بهترین روش برای اطمینان از پیدا شدن, فهمیده شدن؛ و فهرست شدن توسط گوگل, در HTML گذاشتن آن لینک است
- شخصی سازی یا نشان دادن ناوبری منحصر به فرد برای کاربران خاصی از بازدیدکننده در مقایسه با دیگران, به نظر خزنده موتور جستجو مانند مخفی کردن می ماند.
- فراموش کردن لینک کردن به صفحات اصلی در ناوبری سایت - فراموش نکنید, لینک های مسیری خزدن ها برای پیدا کردن صفحات جدید است.
به این دلیل داشتن سیستم ناوبری واضح و پوشه های URL ساختاری کمک کننده بسیار مهم است.
آیا معماری اطلاعات واضحی دارید؟
معماری اطلاعات شیوه ساماندهی و برچسب گذاری محتوای روی یک سایت برای ارتقای بهره وری و قابل کشف بودن توسط کاربران است.بهترین معماری اطلاعات به صورت بصری است ، به این معنی که کاربران برای گردش در وب سایت یا یافتن چیزی نیازی به فکر کردن زیاد ندارند.
آیا از نقشه سایت استفاده میکنید؟
نقشه سایت دقیقاً همان چیزی است که به نظر می رسد, لیستی از URL های سایت که خزنده میتوانند از آنها برای کشف و فهرست محتوا استفاده کنند. یکی از آسان ترین روش های اطمینان از پیدا شدن صفحات مهم توسط گوگل ساخت فایلی با رعایت استاندار های گوگل است. در حالی که ثبت نقشه سایت جایگزین نیاز به ناوبری سایت نیست, مطمئناً می تواند به خزنده ها کمک کند تا لینک های صفحات مهم شما را پیدا کنند.
اگر سایت شما هیچ لینکی از سایت های دیگر ندارد, شما همچنان میتوانید با ثبت نقشه سایت در کنسول جستجوی گوگل, در موتور جستجو فهرست شوید. هیچ تضمینی برای فهرست شدن سایت شما توسط URL ثبت نیست, ولی ارزش امتحان کردن را دارد.
آیا خزنده ها هنگام تلاش برای دسترسی به URL های شما با خطا روبرو میشوند؟
هنگام فرایند خزیدن URL های سایت شما, خزنده ممکن با خطا روبرو شود. میتوایند با استفاده از گزارش “خطاهای خزیدن” کنسول جستجوی گوگل تشخیص دهید کدام URL های باعث این خطا است - این گزارش خطا های سرور و پیدا ندشه را نمایش میدهد. گزارش سرور هم ممکن همین را در کنار گزیده ای از اطلاعات دیگر مانند خزیده های اخیر را نشان دهد, اما برای اینکه دسترسی و بررسی گزارش سرور کاری سختر است, ما در راهنمای مقدماتی به طور کامل درباره آن صحبت نمی کنیم, گرچه شما میتوانید از اینجا درباره آن بیشتر یاد بگیرید.
ثبل از انجام هر کار معناداری با گزارش خطای خزنده, بسیار مهم است که خطاهای سرور و “پیدا نشد” را یاد بگیرید.
کد های سری 400: هنگامی که خزنده های موتور جستجو در اثر خطای سمت کاربر به محتوای شما دسترسی ندارد؟
خطاهای سری 400 خطاهای سمت کاربر هستند, به معنی اینکه URL درخواستی دارای سینتکس بد یا قابل برآورد شدن نیست. یکی از معروفترین خطاهای سری 400, خطای “404, پیدا نشد” است.این خطا ممکن است به دلیل اشتپاه تایپی, صفحات پاک شده, یا انتقال های ناقص اتفاق بیافتد. موقعی که موتور جستجو با خطای 404 روبرو میشود, نمیتواند به URL دسترسی پیدا کند. موقعی که کاربران با خطای 404 روبرو میشوند, ممکن است ناامید و سایت شما ترک کنند.
کد های سری 500: هنگامی که خزنده های موتور جستجو در اثر خطای سمت سرور به محتوای شما دسترسی ندارد؟
خطاهای سری 500 خطاهای سمت سرور هستند, به معنی اینک سروری که صفحه وب در آن قرار دارد نمیتواند درخوسات جستجو کنند یا موتور جستجو را آماده کند. در گزارش “خطاهای خزیدن” کنسول جستجوی گوگل, یک برگه اختصاصی برای این خطاها وجود دارد. این نوع خطا معمولا به دلیل منقضی شدن درخواست برای URL اتفاق میافتد. بنابراین رباط گوگل درخواست را ترک میکند. مستندات گوگل را برای یادگیری رفع مشکلات ارتباطی سرور را ببینید.
خوشبختانه, یک روش برای تفهیم جستجوگران و موتور های جستجوگر برای صفحه انتقال یافته وجود دارد - انتقال (دائمی) 301.

برای مثال بگویید صفحه از example.com/young-dogs به example.com/puppie منتقل شده. موتور های جستجو و کاربران به یک پل عبور از URL قدیمی به جدید نیاز دارند. این پل انتقال 301 است.
تساوی لینک
اگر از انتقال 301 استفاده کنید:اعتبار صفحه از لینک قبلی به لینک جدید انتقال می یابد
اگر از انتقال 301 استفاده نکنید: بدون 301,اعتبار صفحه از لینک قبلی به لینک جدید انتقال نمی یابد
فهرست کردن
اگر از انتقال 301 استفاده کنید: به گوگل کمک میکند تا نسخه جدید صفحه را پیدا کند.
اگر از انتقال 301 استفاده نکنید: نمایش خطاهای 404 به تنهایی هیچ صدمه ای به عملکرد جستجوی سایت وارد نمیکند, اما اجازه دادن به رتبه بندی/افزایش ترافیک صفحات 404 می تواند باعث خارج شدن آنها از فهرست شود, همراه آنها ترافیک و رتبه بندی شان هم از بین میرود.
تجربه کاربری
اگر از انتقال 301 استفاده کنید: می توانید مطمئن باشید کاربران صفحه ای که به دنبال آن هستند را پیدا میکنند.
اگر از انتقال 301 استفاده نکنید: اجازه میدهید تا بازدیدکنددگان به لینک های مرده که آنها را به صفحات خطا به جای صفحه مورد نظرشان لینک کنند, که ممکن برای کاربران خسته کنند به نظر بیاد.
کد وضعیت 301 به معنی انتقال دائمی صفحه به یک آدرس جدید است, بنابراین از انتقال صفحات غیر مرتبط - URL هایی که به محتوایی URL قبلی ربط چندانی ندارد, خودداری کنید. اگر یک صفحه ای برای پرسشی رتبه بندی شده باشد و شما URL ای با محتوای متفاوت را به آن 301 کنید, ممکن است به دلیل اینکه محتوای مرتبط به آن دیگر وجود ندارد, باعث کاهش جایگاه رتبه تان شود. انتقال های 301 بسیار قوی هستند - از آنها با احتیاط استفاده کنید.
همچین میتوانید از گزینه انتقال 302 هم برای انتقال صفحات استفاده کنید, اما این باید برای انتقال های موقت و مواردی که انتقال اعتبار لینک زیاد جدی نیست, استفاده شود. 302 ها همانند راه های انحرافی هستند. به طور موقت برای انتقال ترافیک به مسیری مشخص استافده میکنید, اما نه برای هیشه.
پس از آنکه مطمئن شدید سایت تان برای خزیده شدن بهینه شده است؛ قدم بعدی انجام کارهایی برای اطمینان حاصل کردن از فهرست شدن است.
فهرست کردن: موتور جستجو چگونه صفحات شما بررسی و ذخیره میکند؟
پس از اینکه مطمئن شدید سایت شما میتواند بررسی شود, قدم بعدی این است که مطمئن شوید سایت شما میتواند فهرست شود. درسته - فقط پیدا و خزیده شدن صفحات سایت شما توسط موتور جستجو به معنی ذخیره شدن در فهرست آنها نیست.در بخش قبلی درباره خزیدن صبحت کردیم, درباره اینکه چگونه موتور های جستجو چگونه صفحات شما را کشف میکنند. بعد از پیدا کردن صفحات شما توط خزنده, موتور جستجو آنها را همانند یک مروگر رندر میکند. در روند این کار, موتور جستجو محتوای صفحات را بررسی میکند. تمامی آن اطلاعات ذخیره شده به معنی فهرست شدن است.

رای کسب اطلاعات در مورد نحوه کارکرد فهرست بندی و اینکه چگونه می توانید سایت خود را در پایگاه داده مهم اضفافه کنید ، ادامه مطلب را بخوانید.
آیا میتوانم چگونگی دیده شدن صفحات توسط خزنده گوگل را ببینم؟
بلی, نسخه کش شده وب سایت شما انعکاسی از اسنپ شات (ذخیره شدن آنی اطلاعات) است که آخرین بار توسط رباط گوگل خزیده شده است.
گوگل صفحات وب را در تناوب های مختلف می خزد و پس از آن کش میکند.سایت های شناخته شد با جایگاهی تثبیت شده مانند https://www.nytimes.com که به طور متناوب پست میگذارد بیشتر از سایت های کمتر شناخته شده مانند http://www.rogerlovescupcakes.com (اگر از قبل میدانستید) خزیده میشود.
شما میتوانید با کلیک کردن به فلش رو به پایین کنار URL در SERP و انتخاب “Cached” نسخه کش شده صفحه خود را ببینید.
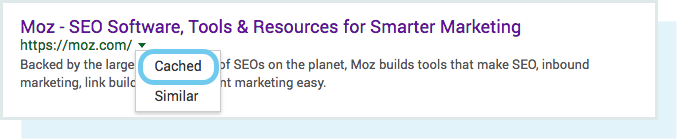
همچنین میتوانید نسخه متنی سایت خود را مشاهده تا ببینید آیا محتوای مهم شما به طور موثری خزیده و ذخیره میشود یا نه.
آیا تابحال صفحات از فهرست حذف شده است؟
بلی, صفحات میتواندد از فهرست حذف شوند.بعضی از دلایل اصلی که ممکن باعث حذف شدن از فهرست شود شامل:
- URL خطای “پیدا نشد 404” با خطای سرور (کد سری 500) برمیگرداند - ااین اتفاق میتواند تصادفی (به صفحه ای که وجود نداره انتاقل 301 انجام شود) و یا به صورت عمدی (صفحه حذف و 404 تبدیل شده زا فهرست پاک و خارج شود)
- URL متا تگ noindex دارد - این تگ توسط صاحب سایت برای راهنمایی کردن موتور جستجو و از قلم انداختن این صفحه از فهرست شدن اضافه میشود.
- URL به صورتی دستی به خاطر نقض قوانین راهنمای وب مستر موتور جستجو جریمه شده و در نتیجه از فهرست خارج شده است.
- URL بدلیل نیازمندی به پسورد برای دیدن صفحات, خزنده از دسترسی به صفحه منع شده است.
- اگر شما فکر میکنید قبلا صفحه تان در فهرست گوگل وجود داشت ولی در حاضر نیست, میتوانید از ابزار بررسی URL برای آگاهی از وضعیت صفحه , یا از دریافت به عنوان گوگل (Fetch as Google) که یک قابلیت درخواست برای فهرست شدن یک صفحه تکی برای فهرست شدن استفاده کنید.(جایزه: “دریافت (Fetch) کنسول جستجوی گوگل ابزاری به نام “render” دارند که به شما اجازه میدهد در صورتی که در نحوه تمامل گوگل با صفحه مشکلی وجود دارد آن را ببینید).
به موتور جستجو بگویید که چگونه سایت شما را فهرست کند
دستورالعملهای متا روباتها
دستورالعملهای متا (یا “متا تگها”) دستورالعملهایی هستند که میتوانید با توجه به روشی که میخواهد با صفحه وب شما برخود شود به موتور جستجو بدهید.
میتوانید به خزنده موتور جستجو چیز هایی مانند “این صفحه را در نتایج جستجو فهرست نکن” یا “” هیچ لینک انتقال به لینکهای داخل صفحه نکن" بگویید. این دستوراعمل ها از طریق متا تگ های رباط های در در داخل <Head> صفحات HTML (اکثر مواقع استفاده میشود) یا از طریق X-Robots-Tag در هدر (header) HTML استفاده میشود.
متا تگ های ربات ها
متاتگ روبات ها را میتوان در داخل <head> کد HTML وب سایتتان قرار دهید. این کار میتواند همه یا یک موتور جستجوی خاص را مستثنی کند. موارد زیر متداول ترین دستورالعمل های متا هستند، بهعلاوه اینکه در چه موقعیت هایی ممکن است از آنها استفاده کنید.
index/noindex به موتور جستجو میگوید که این صفحه برای استفاده مجدد در نتایج جستجو خزیده و نگهداری شود یا نه. اگر از آپشن “noindex” استفاده کنید, شما به گونه ای با خزنده ارتباط برقرار میکنید کی می خواهید صفحه شما از نمایش در صفحه نتایج مستثنی شود. در صورت پیش فرض, موتور های جستجو همه صفحات را فهرست مینند, پس از استفاده ار “index” غیر ضروری است.
چه زمانی ممکن است استفاده کنید: اگر میخواهید که صفحات دارای محتوای کوتاه از اینکس گوگل جا بماند (برای مثال صفحات پروفایل که برای کاربان ساخت میشود) اما همچنان میخواهید برای کاربران قابل مشاهده باشد, می توانید صفحه را “noindex” علامت گذاری کنید.
follow/nofollow به موتور جستجو میگوید که لینک های این صفحه باید دنبال شود یا نه. “follow” باعث میشود تا ربات ها لینک های صفحه دنبال و لینک های انتقالی قدرت را به آن URL ها انتقال دهد. یا اگر “nofollow” را انتخاب کنید, موتور جستجو هیچ لینک انتقال قدرت در این صفحه را منتقل و دنبال نمیکند. در حال پیش فرض, تمامی صفحات فرض میشوند که مشخصه “follow” را دارند.
چه زمانی ممکن است استفاده کنید: nofollow معمولا به همراه noindex و هنگامی که میخواهید که یک صفحه فهرست نشود و از دنبال شدن لینک های صفحه توسط خزنده جلوگیری شود, میتوانید از آن استفاده کنید.
noarchive برای منع ردن موتور جستجو از ذخیره کپی کش شده از صفحه استفاده میشود. در حال پیش فرض, موتورها کپی صفحاتی که فهرست شده اند را نگه خواهند داشت, تا برای از طریق لینک کش در نتایج جستجو برای جستجوگران قابل دسترس باشد.
چه زمانی ممکن است استفاده کنید: اگر یک سایت فروشگاهی دارید و قیمتها به صورت منظم تغییر میکند, بهتر است استفاده از تگ noarchive را برای جلوگیری از دیدن قیمت های منسوخ توسط جستجوگران در نظر بگیرید.
یک مثال از noindex, nofollow متای ربات ها:
<!DOCTYPE html><html><head><meta name="robots" content="noindex, nofollow" /></head><body>...</body></html>
این مثال تمای موتور های جستجو را از فهرست کردن و دنبال کرن لینک های داخل صفحه استثنا می کند. اگر میخواهید چندین خزنده مانند googlebot و را استثنا کنید.
رتبه بندی: موتور های جستجو چگونه URL ها را رتبه بندی می کنند؟
موتورهای جستجو چگونه مطمئن میشوند که هنگامی که کسی یک سوال را نوار سرج تایپ میکنید, در جواب نتایج مربط می گیرند؟ این فرایند با نام رتبه بندی شناخته میشود, یا به مرتب سازی نتایج جستجو بر اساس بیشترین ارتباط تا کمترین ارتباط نسبت یک سوال خاص میگویند.

برای تشخیص ارتباط, موتورهای جستجو از الگوریتمها, یک فراید یا فرمول که توسط آن اطلاعات ذخیره شده به روش های معنی دار بازیابی و مرتب میشود. این الگوریتم ها برای بهبود کیفیت نتایج جستجو در سال های گذشته دچار تغییرات بسیاری شده اند. برای مثال, گوگل به صورت روزانه تنظیمات این الگ.ریتمها را انجام میدهد - بعضی از این بروز رسانی هایی با کیفیت جزئی هستند, در حالی که بقیه, بروز رسانی های هسته/گسترده هستند که برای برخورد با یک مشکل خاص کسترش داده میشود. مانند پنگوئن که برای برخورد با اسپم لیتک ساخته شد.
به چه دلیل الگوریتمها اغلب تغییر میکنند؟ آیا آیا گوگل تلاش میکند ما را روی انگشتان پا نگه دارد؟ درحال که گوگل همیشه درباره چرایی کارهایی که انجام میدهد را افشا نمیکند, ما میدانیم هدف گوگل هنگام تنظیمات الگوریتم ها, لهبود کلی نتایج جستجو است. جوابش این است, در پاسخ به سوالی درباره بروزرسانی الگوریتم ها, گوگل پاسخی با این عبارات را به ما میدهد: “ما همیشه در حال به روزرسانی هایی با کیفیت هستیم.” به این اشاره میکند که اگر سایت شما از تنظیمات یک الگوریتم دجار آسیب شده, آن را در مقابل راهنمای کیفیت گوگل یا راهنمای ارزیاب کیفیت جستجو مقایسه کنید, هر دو شرایط و مقرراتی که موتور های جستجو خاستار آن هستند را به صورت غیر مستقیم میگویند.
موتور های جستجو چه میخواهند؟
موتورهای جستجو همیشه یک چیز می خواهند: ارائه یک جوابهای مفید به سوال جستجو کننده در شکلی که بسیار کمک کننده باشد. اگر واقعیت دارد, چرا نسبت به سال های گذشته متفاوت است؟
آن را مانند یادگیری یک زبان جدید در نظر بگیرید.
در ابتدا, درک آنها از زبان بسیار ابتدایی است — “.See Spot Run” در طول زمان, درک آنها شروع به عمیق شدن میکند, و سپس مفهیم را یاد میگیرند -معنی پشت زبان و ارتباطی که بین کلمات و عبارات است. سرانجام, باتکرار به میزان لازم, دانش آموزان به اندازه زبان را میدانند که میتوانند نکات ریز را بفهمند, و میتوانند به سوال ناقص یا حتی مبهم جواب دهند.
هنگام که موتورهای جستجو شروع به یادگیری یک زبان کردند, بازی دادن سیستم با استفاده از کلک ها و تاکتیک های در واقع مخالف راهنمای کیفیت بود, بسیار راحت بود.پر کردن کلمات کلیدی را در نظر بگیرید. اگر میخواهید باعث رتبه بندی یک کلید واژه خاص مانند “جک های خنده دار” شوید, ممکن است کلمات "جوک های خنده دار" چنید با رد صفحه استفاده و آن را پر رنگ کنید, با امید به اینکه این کار باعث جهش رتبه بندی شما شود.
به جوک های خنده دار خوش آمدید. ما به دنیا خندار ترین جک ها را می گوییم. جک های خنده دار باحا و جذاب هستند. جوک های خنده دار شما منتظر هستند.فقط بشینید و جوک های خنده دار را بخوانید برای اینکه جوک های خنده دار باعث شادی و باحل شدن شما میشوند. چند جوک خنده دار مورد علاقه باحال.
این تاکتیک باعث یک تجربه کاربری افتضاحی میشود, و به جای خندیدن به یک لطیفه خنده دار, مردم توسط مزاحمت و متنی که برای خواندن سخت است بمباران میشوند. ممکن است که در گذشته جواب داده باشد, اما هرگز چیزی که موتورهای جستجو میخواهند نیست.
نقشی که لینک ها در سئو بازی می کنند
هنگامی که درباره لینک ها صحبت میکنیم, منظور ما دو چیز است. بک لینکها یا “لینکهای ورودی” لینکهایی هستند که از وبسایت های دیگر که به وبسایت شما اشاره میکنند, درحالی که لینک های داخلی ,لینک هایی هستند که در سایت شما به صفحات دیگر (در همان سایت) اشاره میکند.

لینکها نقش تاریخی بزرگی در سئو بازی کرده اند. خیلی زود, مورتوهای جستجو نیاز به کمک داشتند تا بفهمند کدام URL قابل اطمینان تر از دیگزی هستند تا به آنها درباره چگونگی رتبه بندی در نتایج جستجو کمک کنند. محاسبه تعداد لینک های که به هر سایتی به آنها کمک میکند تا اینکار را انجام دهند. بکلینک ها بسیار به WoM (دهان به دهان شدن) دریافت اشارات و توجه در زندگی واقعی شباهت دارند. بگذارید یک مثال کافی شاپ فرضی بزنیم, کافه جنی یک مثال است:
- دریافت اشاره و توجه از دیگران = نشانه خوبی از اعتبار - مثال: افراد زیادی به جنی می گویند, کافه جنی بهترین کافه شهر است
- دریافت اشاره و توجه از خود = خودخواهانه, نشانه خوبی از اعتبار نیست - مثال: جنی ادعا میکنید کافه جنی بهترین کافه شهر است
- دریافت اشاره و توجه از منابع کم ارزش و غیر مرتبط = نشان خوبی از اعتبار نیست و ممکن است برای اسپم علامت گذاری شوید - مثال: جنی به مردم که تابحال از کافه اش را ندیده اند پول داده تا از کافه اش تعریف کنند.
- بدون اشارات و توجهات = اعتبار نامعلوم مثال: ممکن است کافه جنی خوب باشد, اما شما نمیتوانید فردی را پیدا کنید که درباره آن نظری داشته باشد, پس نمیتوانید درباره آن مطمئن شوید.
برای همین PageRank (رتبه صفحه) ساخته شد. PageRank (بخشی از هسته الگوریتم گوگل است) یک الگوریتم بررسی کنند لینک است که با نام یکی از موسسان گوگل نامگذاری شده است. PageRank اهمیت یک صفحه وب را با اندازه گیری تعداد و کیفیت لینک های به آن اشاره شده است, اندازه گیری میکند. با فرض اینکه هر چه یک صفحه وب مرتبطتر, مهمتر, و قابل اطمینان تر باشد, لینک های بیشتری دریافت خواهد کرد.
هرچه بک لینک های طبیعی بیشتری از سایت های دارای اعتبار زیاد داشته باشید, شانس شما برای داشتن رتبه بالاتر در نتایج جستجو بیشتر است.
نقشی که محتوا در سئو بازی می کند
اگر لینک ها جستجوگران را به چیزی هدایت نکنند, لینک کردن هیچ فایده ای نخواهد داشت. آن چیز محتوا است! محتوا فقط ملکات نیست; هرچیزی که به درد جستجوگران بخورد - محتوای ویدیوی, محتوای تصویر, و البته محتوای متنی. اگر موتورهای جستجو ماشین پاسخ دهی هستند, محتوا وسیله ای است که موتورها از طریق آن پاسخ ها را تحویل می دهند.
هنگامی که کسی جستجو میکند, احتمال هزاران نتایج وجود دارد, پس موتور جستجو چگونه میفهمد که کدام صفحات برای جستجوکنند ممکن است با ارزش به نظر بیاید؟ بخش عظم تشخیص رتبه صفحه شما به آن عبارت جستجو شده به میران متاقبت محتوای صفحه شما با نیت پرسش دارد. به عبارت دیگر, آیا این صفحه با کلمات که جستجو شده متابقت دارد و به هدفی که جستجوگر به دنبال آن است کمک میکند؟
به همین دلیل به رضایت کابر و اتمام کار (دریافت جواب از محتوای شما) تمرکز کنید, هیچ معیار دقیقی بروی اینکه اندازه محتوای شما چقدر باشد وجود ندارد, چند بار باید شامل یک کلید واژه باشد, یا جه چیزی هایی در تگهای هدر قرار داد, اما تمرکز باید بروی کاربرانی که محتوای شما میخوانند باشد.
امروزه, با صدها و یا حتی هزاران سیگنال رتبه بندی, سه مورد برتر همچنان ثابت مانده اند: لینکهای بهوب سایت شما (که به عنوان سیگنال های اعتبار دهی شخص سوم به شما کمک میکند), محتوای داخل صفحه (کیفیت محتوا و به هدف رساندن جستجوگر), و RankBrain (تعدای از هسته های الگوریتم گوگل).
RankBrain چیست؟
RankBrain اجزای ماشین یادگیری, هسته الگوریتم گوگل است. یادگیری ماشینی یک نرم افزار کامپیوتر است که خودش را از طریق پیشبینی هایی در طول زمان از طریق مشاهدات و داده های آموزش, بهبود میدهد. به عبارت دیگر, همیه در یال یادگیری است, به خاطر یادگیری همیشگی, نتایج جستجو یه صورت پیوسته در حال بهبود است.
برای مثال, اگر RankBrain متوجه شود یک URL با رتبه پایین نسبت یک URL با رتبه بالا نتیجه بهتری به کاربر ارائه میدهد, شما میتوایند روی این موضوع شرطبندی کنید که RankBrain این نتایج را تصحیح میکند, جابجا کردن نتایج مرتبط تر به بالاتر و کاهش رتبه صفحاتی که ارتباط کمتری دارند.

مثل یقیه چیز ها در موتور جستجو, ما نمی دانیم دقیقا شامل چه چیزی است, البته مثل اینکه آنهایی که در گوگل کار میکنند همینطور هستند.
این برای سئو به چه مفهومی است؟
به دلیل ادامه افزایش قدرت نفوذ RankBrain برای ترفیع دادن به مرتبط ترین محتوای مفید, ما باید به برآورده کردن نیت کاربر بیش از بیش تمرکز کنیم. بهترین اطلاعات ممکن و تجربه را برای کاربرانی که ممکن است از صفحه شما استفاده کنند, ارئه دهید, و با این کار شما اولین قدم بزرگ برای عمکرد خوب در دنیای RankBrain برداشته اید.
معیارهای تعامل: ارتباط، علیت یا هر دو؟
با رتبه بندی گوگل, معیارهای تعامل, به طور عمده بخشی از ارتباط و علیت است.
هنگامی که از عبارت معیارهای تعامل استفاده میکنیم, منظورمان دیتایی که چگونگی تعامل کاربر با سایت شما در نتایج جستجو را نشان میدهد, است. این شامل چیزی هایی مانند زیر است:
- کلیک (بازدید از طریق جستجو)
- زمان روی صفحه (زمانی که بازدید کننده قبل از ترک سایت در آن سپری میکند)
- نرخ پرش (درصد جلسات کل سایت هنگامی که کاربران فقط یک صفحه را میبینند)
- Pogo-sticking (کلیک به نتایج ارگانیک و برگشت سریع به SERP برای انتخاب نتیجه دیگر)
تست های زیادی, شامل بررسی فاکتور رتبه بندی خود موز, نشان داده اند که معیارهای تعامل با رتبه های بالاتر مرتبط هستند، اما بحث در مورد علل آن داغ است. آیا معیارهای تعامل خوب فقط نشانی از سایت های دارای رتبه بالا است؟ یا اینکه سایت ها به دلیل معیارهای تعامل خوب دارای رتبه بالایی هستند؟
گوگل چه می گوید؟
درحالی که از عبارت “سیگنال رتبه بندی مستقیم ” استفاده نکرده اند, گوگل درباره آن به صورت صریح بوده, که کاملا از داده های کلیک برای ویرایش SERP و برای سوالات خاضی استفاده میکند.
طبق سخنان رئیس سابق کیفیت جستجوی, اودی منبر:
“رتبه بندی به خودی خود توسط اطلاعات کلیک تحت تاثیر قرار میگرد. اگر ما بفهمیم که برای یک سوال خاص, 80 درصد کاربران بروی شماره 2 نتایج و فقط 10% بروی شماره 1 نتیج کلیک میکنند, بعد از مدتی مفهمیم که احتمالا شماره 2 چیزی است که کاربران آن را میخواهد, پس ما جایشان را عوض میکنیم”
نظر دیگری از مهندس سابق گوگل ادموند لاو که این را تایید می کند.
“کاملا واضح است که هر موتور جستجوی معقولی از داده های کلیکی در نتایج خودشان برای دریافت بازخورد و رتبه بندی برای افزایش کیفیت نتایج جستجو استفاه میکنند. مکانیک استفاده از داده های کلیکی اغلب بصورت اختصاصی است, اما گوگل آشکارا اعلام میکند که از داده های کلیکی به همراه پنتن های آن , در سیستم هایی مانند محتوای تنظیم شده برای رتبه بندی استفاده می کند. "
به دلیل اینکه گوگل نیاز به افزایش و حفظ کیفیت جستجو دارد, به نظر اجتناب ناپذیر است که معیارهای تعامل بیش از همبستگی است, اما به نظر می رسد که گوگل نتواند معیار های تعامل را “سیگنال رتبه بندی” بخواند به خاطر اینکه برای بهبود کیفیت جستجو, و رتبه بندی URL های جداگانه مه محصول جانبی هستند, از این معیارها استفاده میشود.
تست های چه چیزی نشان میدهد؟
تست های بسیاری تایید کرده اند که گوگل ترتیب SERP را بر اساس پاسخ به تعامل جستجوگر تنظیم میکند.
- نتیج تست Fishkin’s 2014 نشان داد که از طریق کلیک 200 نفر در SERP نتیجه 7 ام به جای 1 ام تغییر یافت. جالب است که بهبود رتبه بندی به نظر می آمد بر اساس مکان نفراتی که آن لینک را بازدید کرده بودند, جدا شده و متفاوت بود. موقعیت رتبه در آمریکا به صعود کرد, جایی که اکثر شرت کننده متعلق به آمریکا بودند, در صورتی که صفحه در گوگل کانادا, گوگل استرالیا و غیره, همچنان با رتبه پایین نشان داده شد.
- مقایسه لری کیم از صفحات برتر و زمان سپری شده قبل و بعد از RankBrain, حاکی از این بود که مولفه یادگیری-ماشینی الگوریتم گوگل, صفحاتی که افراد در آن مدت زمان زیادی را سپری نمیکنند, تنزل رتبه میدهد.
- تست دان شاوو نشان داد که رفتار کاربر بر جستجوی محلی و نتایج وابسته به نقشه هم تاثیر میگذارد.
از آن جایی که معیار های تعامل به صورت واضح برای تنظیم کیفیت SERPs, و تغییر جایگاه رتبه به عنوان نتیجه فرعی استفاده میشود, میتوان گفت که سئو باید برای تعامل بهینه شود.تعامل کیفیت عینی در صفحه وب شما را تغییر نمیدهد, اما ارزش شما برای جستجوگران نسبت به نتایج دیگر برای پرسش را ترجیح میدهد. همین دلیل, بعد از هیچ تغییر در صفحه شما یا یکلینک های آن, میتواند باعث کاهش در رتبه بندی شود , در صورتی که جستجوگران طوری رفتار کنند که نشان دهد آنها صفحات دیگر بیشتر دوست دارند.
طبق قوانین رتبه بندی صفحات وب, معیارهای تعامل مانند واقعیت سنج عمل میکند, ابتدا از عوامل عینی مانند لینکها و محتوا باعث رتبه بندی میشوند, سپس معیار های تعمال به گوگل کمک میکند تا آن را تنظیم کنند در صورتی به صورت صحیح این کار را انجام ندادند.
سیر تکاملی نتایج جستجو
قبلا در زمان که موتورهای جستجو فاقد بسیاری از پیچیدگی امروزی بودند, اصطلاح “10 لینک آبی” برای توصیف ساختار مسطح SERP ساخته شد. در زمانی یک جستجو اجرا میشد, گوگل یک صفحه با 10 نتایج ارگانیک, هر بار به یک شکل مشابه نشان میداد.
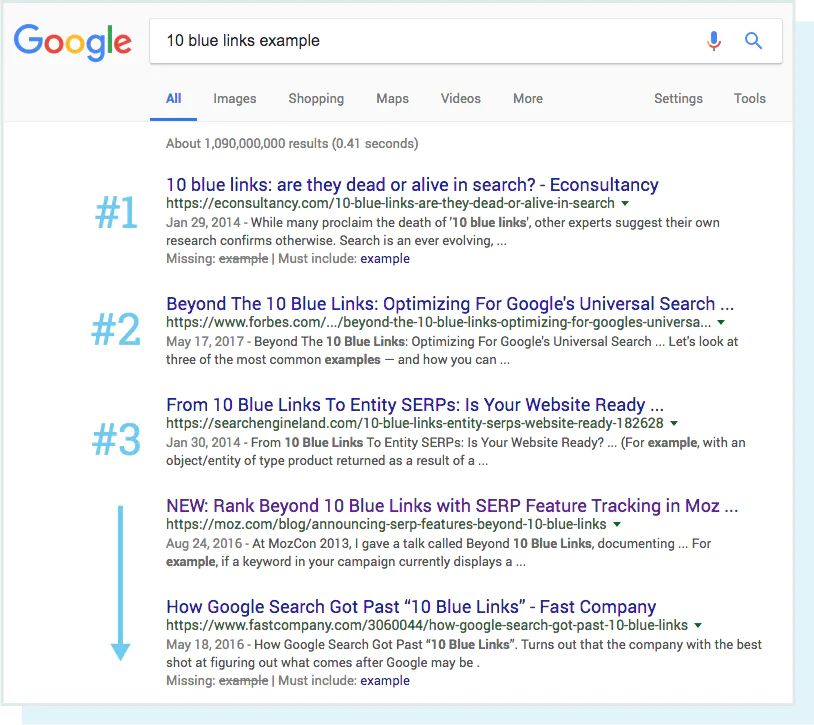
در نمای جستجو, نگه داشتن جای اول همانند نگه داشتن جام مقدس سئو بود, اما بعدا چیزی تغییر کرد. گوگا شروع به اضافه کردن فرمت های جدید در صفحات نتایج جستجو کرد, که ویژگی های SERP نامیده شد. بعضی از این ویژگی های SERP که شامل لیست زیر میشود:
- تبلیغات پولی
- کارت های ویژه (Featured snippets)
- بقیه چه پرسیده اند
- بسته محلی (نقشه)
- پنل دانش
- لینک های سایت
و چیز های جدیدی که گوگل همیشه اضافه میکند. آنها حتی SERP های با نتایج صفر را آزمایش کرده اند, پدیده ای که در آن یک نتیجه از نمودار دانش در SERP با هیچ نتیجه ای در پایین آن بجز گزینه “نتایج بیشتری ببینید” نمایش داده میشود.
به دو دلیل عمده اضافه شدن این ویژگی ها باعث ایجاد ترس می شود. اول اینکه, بسیاری از این ویژگی ها باعث میشود نتایج ارگانیک به بخش پایین تر SERP هل داده شود. نتیجه فرعی دیگر این است که جستجوکننده کمتری به نتایج ارگانیک میکنند زیرا پرسش های بیشتری توسط خود SERP جواب داده میشود.
پس چرا گوگل این کار را میکند؟ همه اینها به تجربه جستجو برمیگرد. رفتار کاربر نشان میدهد که چگونه بعضی پرسش ها بهتر است توسط شکل های یگر محتوا جواب داده شود. چگونه انواع مختلف ویژگیهای SERP با انواع مختلف اهداف پرسش مطابقت دارد.
- هدف پرسش: اطلاعات - ویژگی SERP احتمالی که ممکن نمایش داده شود: کارت ویژه
- هدف پرسش: اطلاعات با یک جواب - ویژگی SERP احتمالی که ممکن نمایش داده شود: اطلااعت بهمراه گرافیک / پاسخ آنی
- هدف پرسش: معاملاتی - ویژگی SERP احتمالی که ممکن نمایش داده شود: خرید
ما در بخش سوم درباره هدف بیشتر صحبت خواهیم کرد, اما فعلا مهم است که بدانید جواب ها میتواند در آرایه وسیعی از شکل های مختلف نمایش داده شود, و چگونه ساختار محتوای شما میتواند در شکل اینکه چگونه در جستجو ظاهر شود تاثیر بگذارد.
جستجوی محلی
یک موتور جستجو مانند گوگل فهرست اختصاصی لیست مشاخص محلی مختص به خود را داراست, که از نتایج جستجوی محلی ساخته میشود. اگر سئو محلی برای یک محل فیزکی که مشتریان میتوانند از آن بازدید کنند (مثلا دندان پزشک) یا کسب و کاری که به محل مشتریان شان مراجعه میکند (مثلا لوله کش), مطمئن شوید که یک لیست رایگان کسب و کار من رایگان گوگل را ادعای مالیک, تأیید و بهینه سازی میکنید.
وقتی صحبت از نتایج جستجوی محلی می شود گوگل از سه فاکتور اصلی برای تعیین رتبه استفاده میکند:
- ارتباط
- مسافت
- برجستگی
ارتباط
ارتباط چگونگی میزان مطابقت کسب و کار محلی با چیزی که جستجوگران دنبال آن هستند میباشد. برای اطمینان از اینکه همه کارهای کسب و کار میتواند با جستجو کننده مرتبط باشد, مطمئن شوید اطلاعات کسب کار کامل و دقیق پر شده است.
مسافت
گوگل از موقعیت مکانی برای ارائه نتایج محلی استفاده میکند. نتایج جستجوی محلی نسبت به مجاورت به یک محل بسیار حساس هستند, که به محل جستجوگر و یا مکان مشخص شده در پرس و جو اشاره است(اگر جستجوگر شمال یکی از آنها باشد).
نتایج جستجوی ارگانیک به مکان جستجوگر حساس هستند, هرچند به ندرت به عنوان نتایج بسته محلی (در اول جستجو نمایش داده میشود) تلفظ می شود
برجستگی
با برجستگی به عنوان یک فاکتور, گوگلبه دنبال پاداش به کسب و کار های مشهور در دنیای واقعی است.علاوه بر برجسته بودن آفلاین یک کسب و کار, گوگل به دنبال برخی عوامل آنلاین برای تعیین رتبه محلی است, مانند:
بررسی ها
به تعداد بررسی که یک کسب و کار محلی دریافت میکند, و مضنون این بررسی ها, تأثیر قابل توجهی در توانایی شان برای رتبه بندی در نتایج محلی دارد.
استناد
یک “استناد به کسب و کار” یا “لیست کسب و کار” مرجعی مبتنی بر وب برای یک کسب و کار محلی است. “NAP” (نام, آدرس, شماره تلفن) در یک پلتفرم محلی (Yelp, Acxiom, YP, Infogroup Localeze و غیره).
رتبه بندی محلی تحت تأثیر تعداد و ثبات استنادات مشاغل محلی است. گوگل برای ساخت مداوم شاخص کسب و کار محلی خود ، داده ها را ازمنایع مختلف دریافت میکند.هنگامی که گوگل چندین مراجعه ثابت به نام, آدرس, شماره تلفن کسب را کار میبیند, این اعتماد گوگل به این داده ها را تقویت میکند. سپس این امر منجر میشود تا گوگل بتواند با اعتماد به نفس بالاتری این کسب و کار نشان دهد, گوگل همچنین از اطلاعات منابع دیگری مانند لینک ها و مقالات موجود در وب استفاده میکند.
رتبه بندی ارگانیک
هنگام تعیین رتبه بندی محلی, از آنجا که گوگل موقعیت وب سایت را در نتایج جستجوی ارگانیک در نظر میگیرد, بهترین روش های سئو را به سئو محلی اعمال میکند.
در بخش بعدی, درباره بهترین تکنیک های داخل صفحه که کمک میکند تا گوگل و کاربران درک بهتری از محتوای شما داشته باشند را باد خواهید گرفت.
[جایزه!] تعامل محلی
گرچه توسط گوگل به عنوان عامل رتبه بندی محلی ذکر نشده است, نقش تعامل فقط با گذشت زمان افزایش می یابد. گوگل با تلفیق داده های جهان واقعی مانند زمان سپری شده و میزان متوسط بازدیدها, بهبود نتایج محلی را گسترش میدهد.
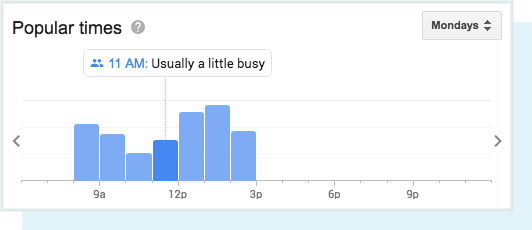
و حتی امکان پرسیدن سوالات تجاری را برای جستجوگران فراهم میکند!

بدون شک اکنون بیش از هر زمان دیگری, نتایج محلی تحت تأثیر داده های دنیای واقعی قرار دارند. این تعامل نحوه رفتار جستجوگران با کسب و کار های محلی و پاسخگویی آنها به جای اطلاعات کاملاً ثابت (و قابل دستکاری) مانند پیوندها و استنادها است. از آنجایی که گوگل میخواهد بهترین, مرتبط ترین کسب و کار را به جستجوگران ارئه دهد, استفاده از معیار های تعامل در زمان به موقع برای سنجش کیفیت و ارتباط کاملا منطقی به نظر می رسد.
نیازی نیست از زیر و بم الگوریتم گوگل مطلع شیود (همیشه یک راز باقی می ماند), اما باید یک درک پایه از چگونگی پیدا کردن موتور جستجو, تفسیر, ذخیره کردن, رتبه محتوا داشته باشد. به این دانش مجهز شدید, بیایید در مورد انتخاب کلمات کلیدی برای محتوا یاد بگیریم که در بخش سوم (پژوهش کلیدواژه) به آن میپردازیم.
نوشته شده توسط برتنی مولر, منبع موز